【Python入門】機械学習・データ分析におすすめな外部ライブラリ5選

Pythonには、読み込むことでプログラム内部の機能拡張が可能な「ライブラリ」という仕組みが存在します。
このうち、外部からインストールする必要があるものを「外部ライブラリ」というのですが、種類が多くどれを入れておけばいいのか迷われる方もいるかもしれません。
この記事では、機械学習やデータ分析の分野で役に立つおすすめライブラリを5つ紹介します。
機械学習・データ分析におすすめなライブラリ5選
外部ライブラリには、より専門的な演算処理に特化した関数やクラスが多く存在しています。
これから紹介するライブラリは、開発現場でも多く用いられるものばかりですので、ぜひ参考にしてみてください。
NumPy
NumPyは、より高度かつ高速な演算処理に特化した外部ライブラリです。
なかでも、ベクトルや行列といった多次元配列の操作に長けたクラス・関数を多く保有しているのが特徴となっています。
例えば、NumPyモジュールに含まれるarray()関数を使うと、リストやタプルから多次元配列を作成することができます。
また、NumPyでは「ndarray」と呼ばれる特殊な形式で多次元配列を扱います。
import numpy as np # numpyをnpとして読み込み
# array関数にて、多重リスト(リスト内にリストを保持)よりndarrayを作成
mt = np.array([[1,2,3], [4,5,6], [7,8,9]])
print(mt) # mtの中身を表示
print(type(mt)) # mtのデータ型を表示= 実行結果 =
[[1 2 3]
[4 5 6]
[7 8 9]]
<class 'numpy.ndarray'>Pandas
Pandasも、NumPyと同様に高度かつ高速な演算処理に特化した外部ライブラリです。
特に、データ分析の前処理に長けたクラス・関数を多く保有しているといった特徴をもっています。
また、Pandasでは 「DataFrame(データフレーム)」 と呼ばれる特殊な形式で2次元データを扱います。
import pandas as pd # pandasをpdとして読み込み
# DataFrame関数にて、多重リスト(リスト内にリストを保持)よりデータフレームを作成
df = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]])
print(df) # dfの中身を表示
print(type(df)) # dfのデータ型を表示= 実行結果 =
0 1 2
0 1 2 3
1 4 5 6
2 7 8 9
<class 'pandas.core.frame.DataFrame'>実行結果の上側と右側に表示されている「0 1 2」は、行・列の番号を表しています
Matplotlib
Matplotlibは、データの可視化(グラフの作成)に特化したライブラリです。
折れ線グラフや棒グラフ、散布図などデータの種類に合わせて様々なグラフを作成することができます。
またライブラリの特性上、NumPyやPandasなどのデータの演算・加工用ライブラリと組み合わせて使う場合が多いです。
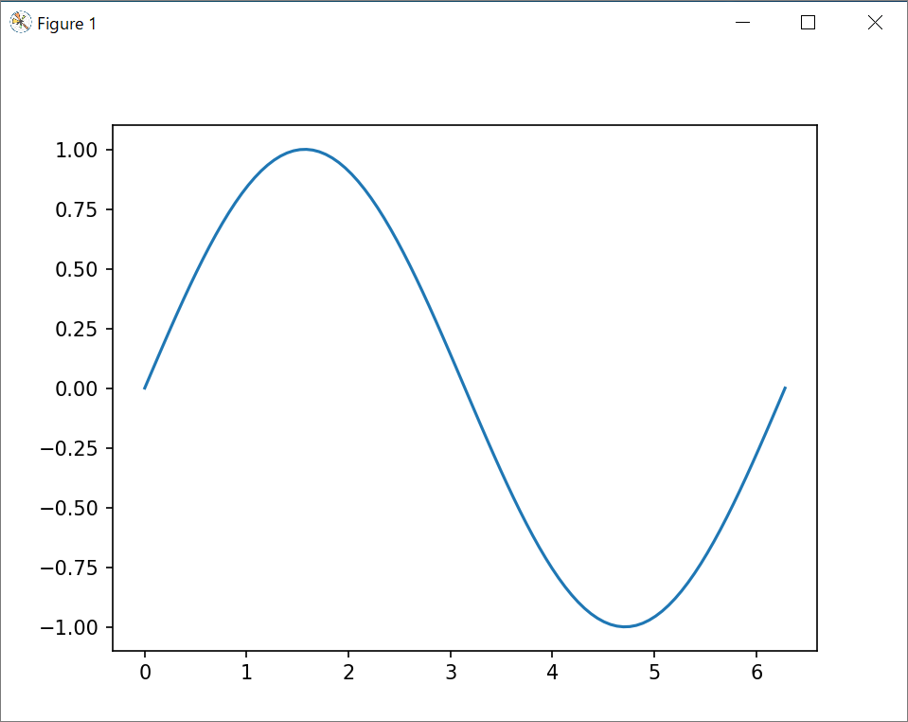
import numpy as np # numpyをnpとして読み込み
import matplotlib.pyplot as plt # matplotlibのpyplotモジュールをmplとして読み込み
x = np.linspace(0, 2*np.pi, 100) # 0~2πの間を500に分割する(=X軸の間隔)
y = np.sin(x) # y=sin(x)として、yの値を決定
plt.plot(x, y) # xとyの値をもとに、データをプロットする
plt.show() # グラフを表示= 実行結果 =
seaborn
seabornは、グラフ描画において表示スタイルの変更が可能な外部ライブラリです。
線の太さやグリッド表示の有無など、様々な調整ができるようになっています。
先ほど紹介した Matplotlib と組み合わせて使用すると、より可視化したデータを見やすくすることができます。
特に、2つ以上のグラフを重ねて表示する場合など、情報量が多い場面で重宝するライブラリとなっています。
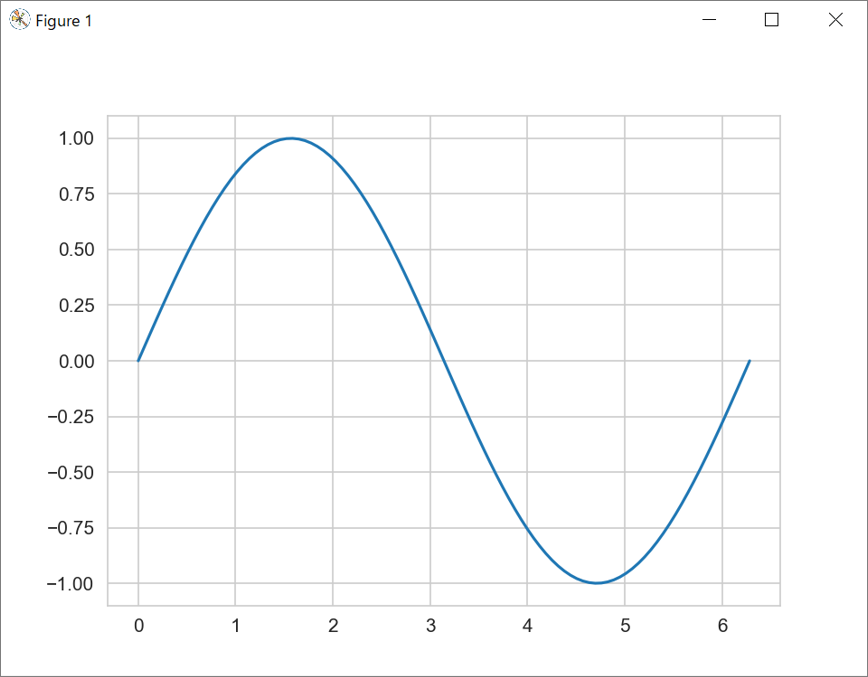
import numpy as np # numpyをnpとして読み込み
import matplotlib.pyplot as plt # matplotlibのpyplotモジュールをmplとして読み込み
import seaborn as sns # seabornをsnsとして読み込み
x = np.linspace(0, 2*np.pi, 100) # 0~2πの間を500に分割する(=X軸の間隔)
y = np.sin(x) # y=sin(x)として、yの値を決定
sns.set_style("whitegrid") # 背景にグリッド線を表示
plt.plot(x, y) # xとyの値をもとに、データをプロットする
plt.show() # グラフを表示= 実行結果 =
scikit-learn
scikit-learnは、機械学習向けの処理に特化したライブラリです。
サポートベクターマシンやランダムフォレストなど、データの学習や予測に必要な操作が数多く組み込まれています。
機械学習になじみのない方は少し難しく感じるかもしれませんが、要するに
- 学習用に準備されたデータを分析する
- 分析したデータから、ルールや法則性を見つけ出す
- 見つけ出したルールをもとに、データを自動で識別・予測できるようにする
上記のような学習を行うため、「データの特性に合わせて様々な手法が備わっている」という認識でOKです。
「画像認識」や「音声認識」も、機械学習によって識別が可能となった技術の一つです
まとめ
この記事では、機械学習やデータ分析の分野で役に立つおすすめライブラリについて紹介しました。
外部ライブラリを上手に活用すれば、複雑な処理や操作に必要な記述の手間を大幅に減らすことができます。
どれも高度なプログラムを組むうえでは必須なライブラリですので、ぜひ参考にしてみてください。